Federated K-Means¶
In this section, we attempt to form a federated k-means algorithm to preserve the privacy of the individual labs.
Federated learning: First introduced by Google, federated learning trains an algorithm across multiple decentralized servers/devices with local data samples. There is no data sharing between servers. This is in contrast to the standard way of training a machine learning algorithm where all of the training dataset is uploaded to one server. This technique address critical issues relating to data privacy and security
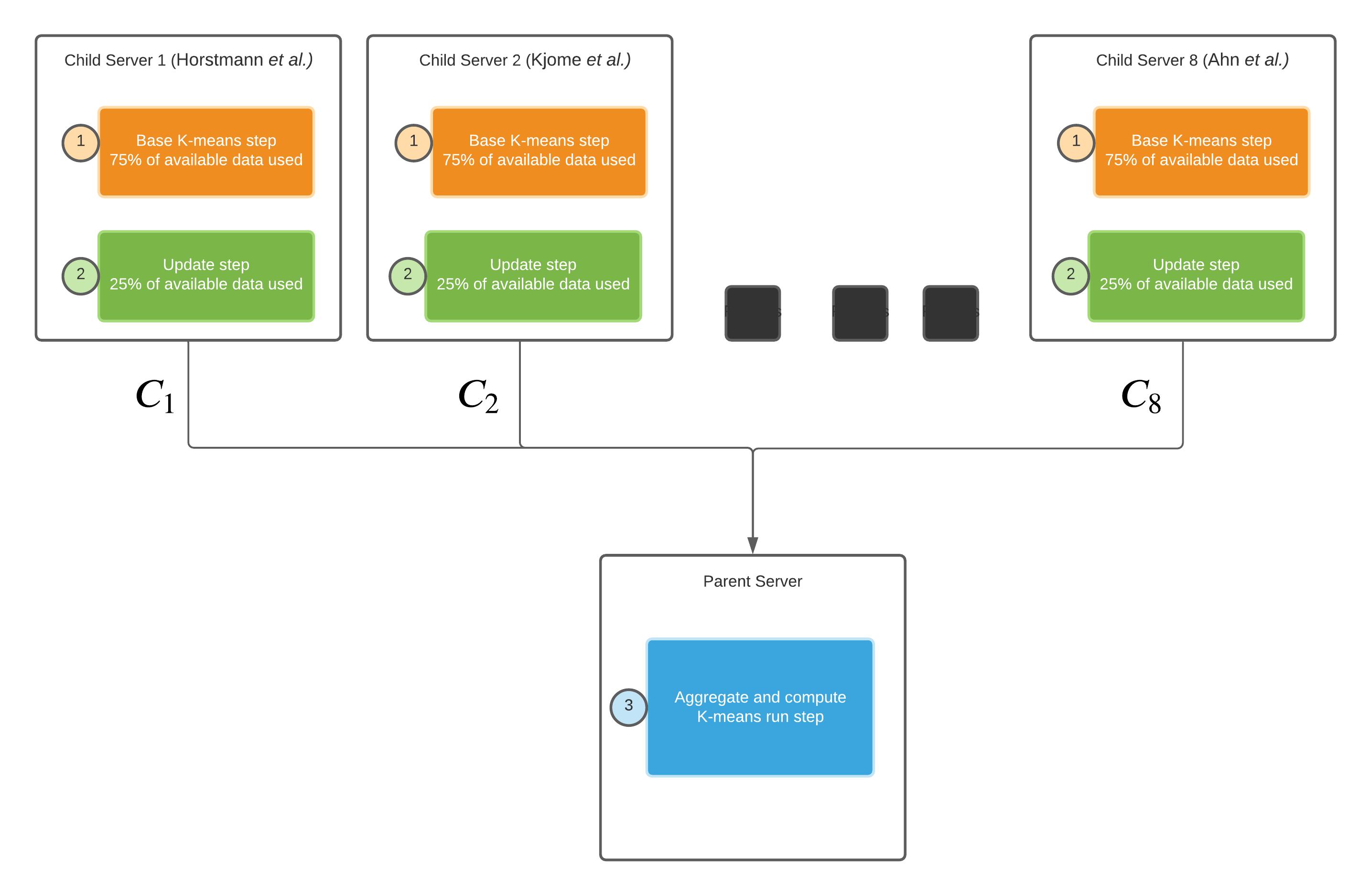
Fig. 1 Workflow of Federated K-means Note: child servers 2 to 7 are obscured¶
Child Server (Study):¶
1. Base k-means:¶
The original K-Means algorithm is only trained on a given dataset once. There is no update method. In this approach, we split a study’s dataset 75:25. 75% of a study’s data is trained using normal K-means as part of step 1. It is important to note that all child servers are independent of one another.
2. Update:¶
In an attempt to resemble real-world federated learning where a new data point is generated on a device, we add an update step to base K-means. Rather than recompute k-means, we iterate through the remaining 25% of data and perform the following steps
Convert new data point to NumPy array
Find the minimum Euclidean distance between that new point \(X_{i}\) and the cluster centres (T) to find the closest cluster centre (\(C_{i}\)). \( Minimum Distance = min((X_{i} - C_{1})^2.............(X_{i} - C_{T})^2) \)
Transform the cluster centre \(C_{i}\) by doing the operation below. N equals the number of participants assigned to that cluster thus far i.e. before the new data point : \( TransformedClusterCentre = \frac{((C_{i} * N) + X_{i})}{N+1} \)
Then, the new data point is added to the cluster, and the transformed cluster centre is the new cluster centre.
Parent Server:¶
3. Aggregate & Compute K-means run:¶
Once all child devices have completed their update phase, their cluster centres are added to the parent server. Then, we compute another K-means run to find the optimal number of k centroids.
from sklearn.cluster import KMeans
import pandas as pd
import numpy as np
dim_reduced_2d = pd.read_csv('data/dim_reduced_2d.tsv', sep="\t")
dim_reduced_3d = pd.read_csv('data/dim_reduced_3d.tsv', sep="\t")
Here, we are just creating variables to hold the data from each study.
studies_list = ['Horstmann', 'Kjome', 'Maia', 'SteingroverInPrep', 'Premkumar','Wood', 'Worthy', 'Ahn']
for study in studies_list:
globals()[f'{study}_study'] = dim_reduced_2d[dim_reduced_2d['study'] == study]
Child K-means class¶
class child_kmeans(KMeans):
"""
A python class that executes the original k-means algorithm on 75% of the available data
from a study. Leftover data is used to update the cluster centres
as described above. Inherits from scikit-learn's K-means class
"""
def __init__(self,
df,
n_clusters):
super().__init__(n_clusters=n_clusters, random_state=42)
self.df = df
self.update_df, self.base_df = np.split(df, [int(.25*len(df))])
# map cluster index to number of particpants e.g. <0:77>
self.cluster_index_num = dict()
# map cluster index to number of particpants e.g. <0:array([-0.96292967, 1.03276864])>
# Necessary as numpy array is unhashable
self.index_cluster_centre = dict()
def find_closest_cluster(self, new_data_point):
min_dist = float("inf")
min_cluster_centre= None
cluster_index = None
for current_key, cluster in self.index_cluster_centre.items():
current_dist = (np.sum(np.square(new_data_point - cluster)))
if current_dist < min_dist:
min_cluster_centre = cluster
min_dist = current_dist
cluster_index = current_key
return cluster_index, min_cluster_centre
def update(self):
for index, row in self.update_df.iterrows():
new_data_point = np.array(row)
cluster_index, closest_cluster = self.find_closest_cluster(new_data_point)
num_subjects = self.cluster_index_num[cluster_index]
self.index_cluster_centre[cluster_index] = np.divide(((closest_cluster * num_subjects) + new_data_point), num_subjects+1)
self.cluster_index_num[cluster_index] += 1
def create_maps(self):
cluster_indexes, counts = np.unique(self.labels_, return_counts=True)
self.cluster_index_num = {cluster_index:count for cluster_index, count in zip(cluster_indexes, counts) }
self.index_cluster_centre = {cluster_index: self.cluster_centers_[cluster_index] for cluster_index in cluster_indexes}
def run(self):
super().fit(self.base_df)
self.create_maps()
self.update()
updated_cluster_centres = [np.array(cluster_centre) for cluster_centre in self.index_cluster_centre.values()]
return updated_cluster_centres
Parent K-means class¶
class parent_kmeans(KMeans):
"""
A python class that retrieves cluster centres from
each study, and then computes another k-means algorithim
"""
def __init__(self,n_clusters) -> None:
super().__init__(n_clusters=n_clusters, random_state=42)
self.cluster_centres_studies = []
self.federated_cluster_centres = None
def add(self, cluster_centre):
self.cluster_centres_studies.extend(cluster_centre)
def update_cluster_centre(self):
super().fit(self.cluster_centres_studies)
def get_new_centres(self):
return self.cluster_centers_
parent_server = parent_kmeans(n_clusters=3)
for study in studies_list:
# First retrieving the cluster centres from a study
study_cluster_centres = child_kmeans(globals()[f'{study}_study'].iloc[:,2:], n_clusters=3).run()
# Adding that information to the parent server
parent_server.add(cluster_centre=study_cluster_centres)
# Calculating the new federated cluster centres
parent_server.update_cluster_centre()
# Retrieving the cluster centres from Federated K-means and normal K-means
fkm_cluster_centres = parent_server.get_new_centres()
km_clusters_centres = KMeans(n_clusters=3,random_state=42).fit(dim_reduced_2d.iloc[:,2:]).cluster_centers_
Evaluation¶
Before evaluating the results, an important consideration should be noted. As with any K-Means algorithm, results may vary with each run or input seed of the algorithm as the algorithm’s performance is heavily dependent on the initial clusters chosen. We evaluate our algorithm on the 2d dataset with k=3 and seed=42.
def calulate_SSE(df, fkm_cluster_centres, km_clusters_centres):
"""
Calculates k-mean's objective function (Sum Square Error) for both federared K-means
algorithm and the original K-means algorithm
:param df: Dataframe containing data from the many labs paper
:param fkm_cluster_centres: Cluster centres of the Federated K-means Algo.
:param km_clusters_centres: Cluster centres of the original K-means Algo.
"""
df["fkm_SSE"] = None
df["km_SSE"] = None
for index, subject in df.iterrows():
subject_dim = np.array(subject[["component_1","component_2"]])
df.iloc[index, -2] = min([(np.sum(np.square(subject_dim - cluster))) for cluster in fkm_cluster_centres])
df.iloc[index, -1] = min([np.sum(np.square(subject_dim - cluster)) for cluster in km_clusters_centres])
return df
evaluate_2d_df = calulate_SSE(dim_reduced_2d, fkm_cluster_centres, km_clusters_centres)
print(f'Federated K-mean SSE: {evaluate_2d_df["fkm_SSE"].sum()}')
print(f'K-mean SSE: {evaluate_2d_df["km_SSE"].sum()}')
Federated K-mean SSE: 1498.2800508864195
K-mean SSE: 1362.1960103577223
Our chosen approach only results in a approximate 10% increase in SSE compared to the original centralized K-means algorithm.